Handbook
Welcome to the wonderful world of the Reatom library! 🤗
This robust solution is designed to become your go-to resource for building anything from micro libraries to comprehensive applications. We know the drill - regular development would often mean having to repeatedly implement similar high-level patterns, or relying on external libraries, both equally challenging in achieving perfect harmony in interface equality and semantics compatibility, performance and the principles of ACID, debugging and logging experience, tests setup and mocking.
To make your development journey smoother, we’ve developed the perfect primitives (atom and action) and a set of packages on top of them. Together, they address and simplify these challenges, allowing you more room to get creative.
This guide will introduce you to all the features of Reatom, including the core concepts and mental model, the ecosystem, and the infrastructure.
TL;DR
Need a fast start? Here is a list of key topics:
@reatom/coreprovides basic primitives to build anything. Just put your state in theatomand your logic in theaction.- All data changes should be immutable, like in React or Redux.
ctxis needed for better debugging, simple tests, and SSR setup.- @reatom/async will help you manage network state.
- There are many other helpful packages, check the Packages section in the sidebar.
- @reatom/eslint-plugin will automatically add debug names to your code, and @reatom/logger will print useful logs to your console.
- Template repo
Installation
The core package is already feature-rich and has excellent architecture. You can use it in small apps as is or in large apps and build your own framework on top of it.
However, for most apps and developers, we have built a “framework” package, which is a collection of the most useful packages. Technically, the “framework” package is just a set of reexports, but it simplifies the way Reatom is used and maintained. Your imports are shortened, your direct dependencies are shortened, and it becomes easier to update.
All of this works fine with tree shaking, don’t worry about the bundle size, Reatom development is very focused on this aspect.
This guide will follow you through all the main features, so we will install infrastructure packages too such as “testing” and “eslint-plugin”. We also have the “logger” package, but it is already included in the framework and doesn’t need an additional part in the installation script.
The final non-general part of the installation script is a bindings package, depending on your stack. Usually, these days, users need the “@reatom/npm-react” adapter package, but we have adapters to other view frameworks too. By the way, the “npm-” prefix is used in all adapter packages to prevent naming collisions with the ecosystem packages, as the NPM global namespace is widely used and many common words are occupied by some packages.
npm i @reatom/framework @reatom/testing @reatom/eslint-plugin @reatom/npm-reactA note about the ecosystem: all packages that start with “@reatom/” are built and maintained in the monorepo. This approach allows us to have precise control over the compatibility and stability of all packages, even with minor releases. If you want to contribute a new package, feel free to follow the contributing guide. We have a package-generator script that will bootstrap a template for a new package, and all we require from your side are the sources, tests, and a piece of docs ;)
Reactivity
Let’s get some simple form code and make it reactive to enhance its scalability, debuggability, and testability. Of course, the reason to use a separate state manager in this form is for example purposes, and the profit will increase as your real application grows.
<input id="NAME" /><p id="GREETING"></p>export let name = localStorage.getItem('name') ?? ''const updateName = (newName) => { name = newName localStorage.setItem('input', name) greeting = `Hello, ${name}!`}
export let greeting = ''
// view bindingsNAME.value = nameNAME.oninput = (event) => { updateName(event.target.value) GREETING.innerText = greeting}greeting = `Hello, ${name}!`GREETING.innerText = greetingSo, is the code above pretty dumb, yeah? But it already messy and have unexpected bugs.
The first obvious problem is code duplication - we write Hello... and innerText assignment twice and it couldn’t be fixed. Of course, you can move it to a separate function, but you still need to call that function two times: for initialization and for updating.
The second serious problem is code coupling. In the code above, the logic for updating the greeting is stored in the name update handler, but the actual data direction is inverse: the greeting depends on the name. In this minimal example, the problem may not seem important. However, in real application code organization and business requirements are much more complex, and it is easy to lose the sense of the logic—why one thing changes others or vice versa.
Reactive programming, in general, solves these problems. It enables you to accurately describe the dependent computations of your data in the correct manner, scoped to each domain. Let’s do it with Reatom. We need to wrap our changeable data in the atom function. If you put a primitive value into the created atom, you will allow the state of the atom to be changed. If you put a computed function into the atom, you will get a readonly atom that will automatically recompute when a dependent atom changes, but only if the computed atom has a subscription.
export const nameAtom = atom(localStorage.getItem('name') ?? '')nameAtom.onChange((ctx, name) => { localStorage.setItem('input', name)})
export const greetingAtom = atom((ctx) => { const name = ctx.spy(nameAtom) return `Hello, ${name}!`})
// view bindingsNAME.value = ctx.get(nameAtom)NAME.oninput = (event) => { nameAtom(ctx, event.target.value)}ctx.subscribe(greetingAtom, (greeting) => { GREETING.innerText = greeting})Now, we have the same amount of code, but it is much better organized and structured. And we have ctx now! It gives us superpowers for debugging, testing, and many other helpful features. We’ll cover it later.
Data consistency
There is still a problem, one of the most serious, which is hard to manage in all cases and even harder to debug. This problem is data consistency. If the code is running in an environment that actively uses the storage (localStorage), you could encounter a quota error when trying to set new data. In this case, the user will see the input changes, but no greeting updates. Certainly, it is a good reason to wrap the storage processing code in a try-catch block, but in real development, these kinds of errors (and many others!) are considered too rare to be handled. This is a practical approach, but it would be cool to fix these kinds of problems with just one elegant pattern, yeah?
Reatom provides excellent features for handling data consistency. All data processing is accumulated and saved in the internal store only after completion. If an error occurs, such as “Cannot read property of undefined,” all changes will be discarded. This mechanism is very similar to how React handles errors in renders or how Redux handles errors in reducers. This is a well-known pattern from database theory and is described in A part of ACID. And this is the reason why atom is named so.
This transaction logic works automatically under the hood, and all you need to worry about is keeping the data immutable. For example, to update an array state, you should create a new one using the spread operator, map, filter, and so on.
Reatom proposes the ctx.schedule API, which allows you to separate pure computation and effects. The handy thing is that you can call ctx.schedule anywhere, as the context follows through all primitives and callbacks of Reatom units. This scheduler will push the callback to a separate queue, which will be called only after all pure computations. It is much safer and helps you manage your data flow better.
So, let’s do a small refactoring.
export const nameAtom = atom(localStorage.getItem('name') ?? '')nameAtom.onChange((ctx, name) => { ctx.schedule(() => { localStorage.setItem('input', name) })})That’s all! Now your pure computations and effects are separated. An error in local storage logic will not affect the results of the atoms computations.
Another cool feature of the schedule API is that it returns a promise with the data from the callback. This allows you to easily manage various data-related side effects, such as backend requests, step-by-step. In the next chapter, we will introduce action as a logic container and explore async effects.
Actions
Let’s enhance our form to create something valuable. Maybe a login form?
<form id="FORM"> <input id="NAME" /> <p id="GREETING"></p> <input type="submit" /></form>export const nameAtom = atom(localStorage.getItem('name') ?? '')nameAtom.onChange((ctx, name) => { ctx.schedule(() => { localStorage.setItem('input', name) })})
export const greetingAtom = atom((ctx) => { const name = ctx.spy(nameAtom) return `Hello, ${name}!`})
export const submit = action(async (ctx, event) => { event.preventDefault() const name = ctx.get(nameAtom) const body = new FormData() body.append('name', name)
const response = await ctx.schedule(() => fetch('/api/submit', { method: 'POST', body: body }), ) if (!response.ok) { alert(`Oups, the API is doesn't exist, this is just a test.`) }})
// view bindingsNAME.value = ctx.get(nameAtom)NAME.oninput = (event) => { nameAtom(ctx, event.target.value)}ctx.subscribe(greetingAtom, (greeting) => { GREETING.innerText = greeting})FORM.onsubmit = (event) => { submit(ctx, event)}That’s all for now. The remaining part of the tutorial is a work in progress. 😅
…
Debug
The immutable nature of Reatom gives us incredible possibilities for debugging any kind of data flow: synchronous and asynchronous. The internal data structures of atoms are specially designed for simple investigation and analytics. The simplest way to debug data states and their causes is by logging ctx, which includes the cause property with internal representation and all meta information.
Let’s check out this example.
export const pageAtom = atom(1, 'pageAtom').pipe( withReducers({ next: (state) => state + 1, prev: (state) => Math.max(1, state - 1), }),)
export const issuesReaction = reatomResource(async (ctx) => { const page = ctx.spy(pageAtom) return await ctx.schedule(() => request<IssuesResponse>( `https://api.github.com/search/issues?q=reatom&page=${page}&per_page=10`, ctx.controller, ), )}, 'issuesReaction').pipe(withDataAtom({ items: [] }))
export const issuesTitlesAtom = atom((ctx) => { console.log('issuesTitlesAtom ctx', ctx) return ctx.spy(issuesReaction.dataAtom).items.map(({ title }) => title)}, 'issuesTitlesAtom')Here is what you will see from issuesTitlesAtom ctx log (some data below omitted for a short, check the sandbox for real log.
{ "proto": { "name": "issuesTitlesAtom" }, "state": [...], "cause": { "proto": { "name": "issuesReaction.dataAtom" }, "state": { "total_count": 202, "incomplete_results": false, "items": [] }, "cause": { "proto": { "name": "issuesReaction.onFulfill" }, "state": [], "cause": { "proto": { "name": "issuesReaction" }, "state": [], "cause": { "proto": { "name": "pageAtom" }, "state": 1, "cause": { "proto": { "name": "pageAtom._next" }, "state": [] } } } } }}As you can see, the cause property includes all state change causes, even asynchronous ones. But what are the empty arrays in action states? These are lists of action calls (with payload and params) that only exist during a transaction and are automatically cleared to prevent memory leaks.
To view persisted actions data and explore many more features, please try reatom/logger!
By the way, you could inspect all atom and action patches by ctx.subscribe(logs => console.log(logs)).
Lifecycle
Reatom is a heavy inspired by actor model, which important quality is that each component of the system is isolated from the others. This isolation is achieved by the fact that each component has its own state and its own lifecycle. This is the same for an atoms. We have API that allows you to create a system of components that are independent of each other and can be used in different modules with minimum setup. This is the main advantage of Reatom over other state management libraries.
For example, you could create some data resource, which depends of a backend service and will connect to the service only when the data atom used. This is a very common case for a frontend application. In Reatom you could do it with lifecycle hooks.
import { atom, action } from '@reatom/core'import { onConnect } from '@reatom/hooks'
export const listAtom = atom([], 'listAtom')export const fetchList = action( (ctx) => ctx.schedule(async () => { const list = await api.getList() listAtom(ctx, list) }), 'fetchList',)onConnect(listAtom, (ctx) => fetchList(ctx))What happens here? We want to fetch the list only when a user comes to the relative page and the UI subscribes to listAtom. It is work same as useEffect(fetchList, []) in React.js. As an atoms represents a shared state the connection status is “one for many” listeners, which means an onConnect hook triggers only for a first subscriber and not calling for a new listeners. It is super useful coz you could use listAtom in many components to reduce props drilling, but request the side effect only once. If an user leaves the page and all subscriptions gone the atom marks as unconnected, an onConnect hook will called again only when a new subscription occurs.
The important knowledge about Reatom atoms is that they are lazy. It means that they will be connected only when they will be used. This usage is possible only by ctx.subscribe, but the magic of underhood Reatom graph is that ctx.spy apply connections too! So, if you have a main data atom, compute some others atoms from it and use them in some components, the main atom will be connected when some component will be mounted.
const filteredListAtom = atom((ctx) => { const list = ctx.spy(fetchList) return list.filter(somePredicate)})ctx.subscribe(filteredListAtom, sideEffect)The code above will trigger listAtom connection and fetchList call as expected.
Notice that the links between computed atoms have only a one direction -
filteredListAtomis a dependency oflistAtom, in other wordsfilteredListAtomis a dependent fromlistAtom.listAtomdoesn’t know aboutfilteredListAtom. If you haveonConnect(filteredListAtom, cb)and onlylistAtomhave a subscription the callback will not be called.
When you use an adapter package, like npm-react, under the hood it will use ctx.subscribe to listen the fresh state of the atom. So, if you connect an atom with useAtom, the atom will be connected when the component will be mounted.
const [filteredList] = useAtom(filteredListAtom)Now, you have lazy computations and lazy effects!
This pattern allow you to stay control of data neednes in view layer or any other consumer module, but do it implicitly, and explicitly for data models. You don’t need extra start actions or something like that. It is a more clean and scalable way to design your code, with better ability to reuse a components.
A lot of cool examples you could find in async package docs.
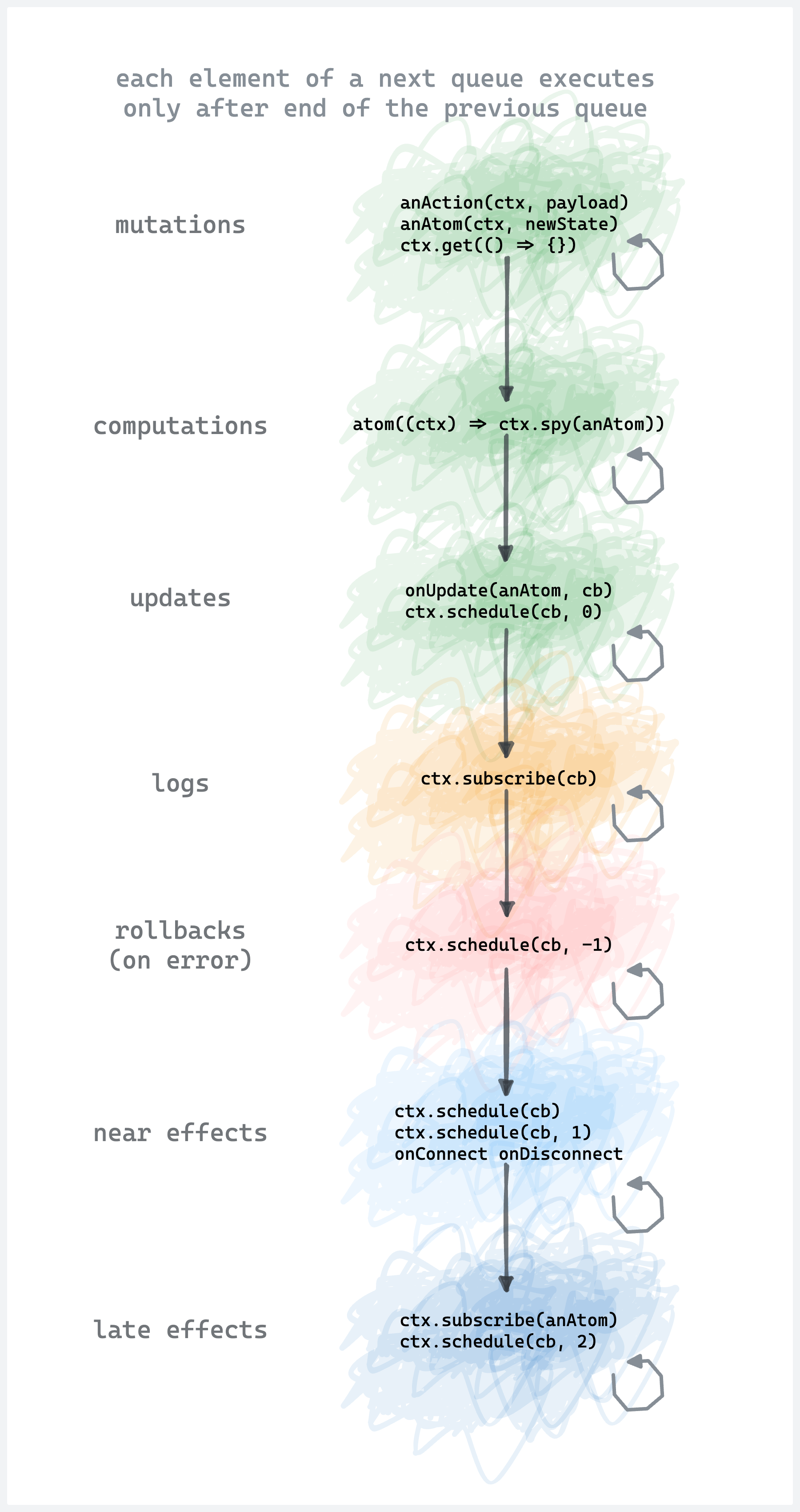
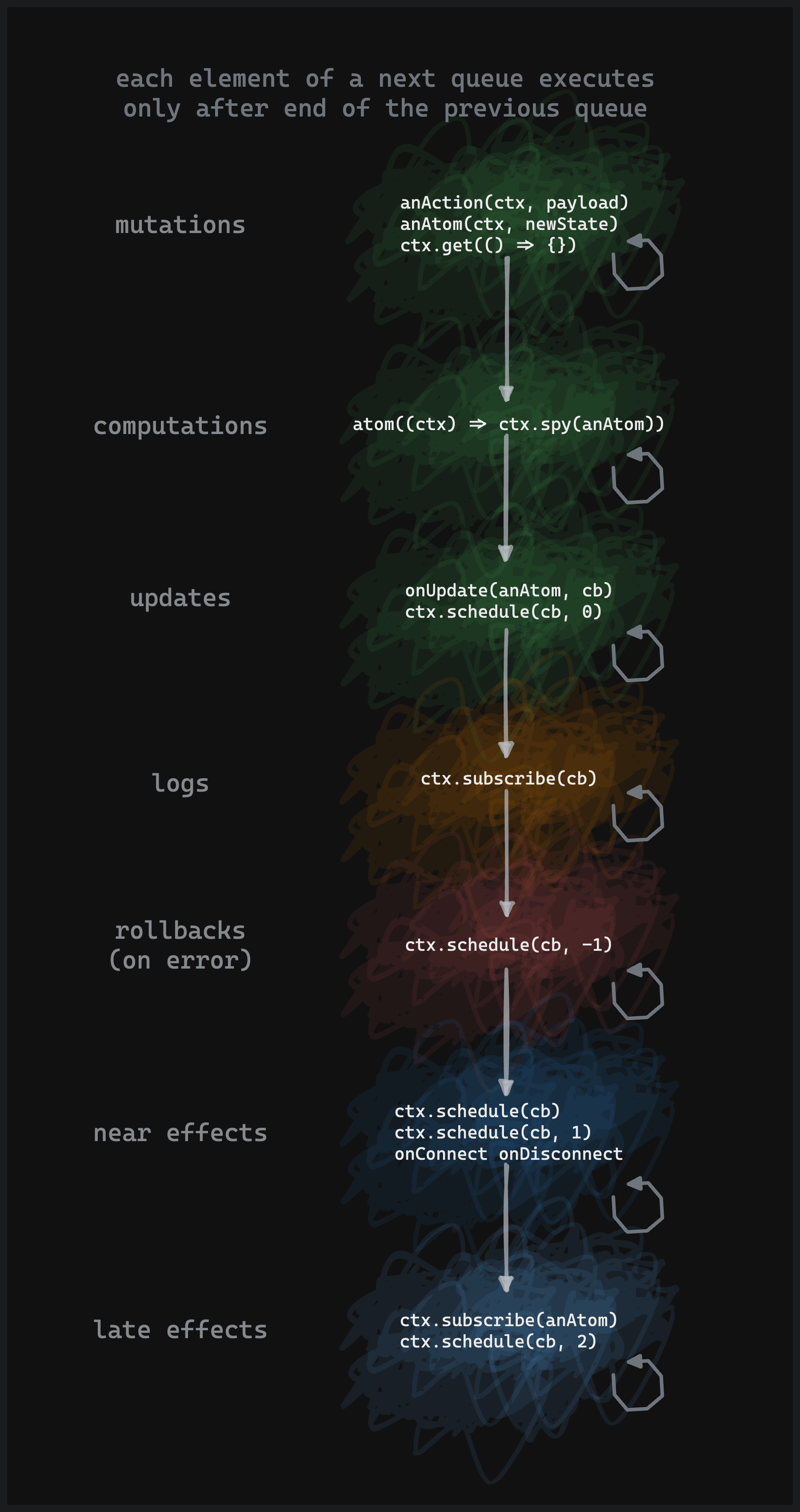
Lifecycle scheme
Here is a scheme of the execution order of the build-in queues.
Check ctx.schedule docs for more details about the ability to use the queues.